I started working on a project clustering a trait database so that I can get up to 15 clusters of species groups. Hence I am refreshing on the potential algorithms I could use.
Algorithms
There are different types of clustering alogrithm with different distance measures, including density-based, distribution-based, centroid-based, hierarchical-based, model-based.
The common 4 distances measures are Enclidaen, Manhattan, Correlation and Eisen.
We focus on a few for the moment.
Partitioning Clustering
K-means clustering (centroid-based)
K-Medoids (PAM)
CLARA
DBSCAN (density-based spatial clustering of applications with noise)
Hierarchical Clustering
Agglomerative Hierarchy clustering algorithm
Spectral Clustering
Cluster GoF (clValid)
Internal: the connectivity, the silhouette coefficient and the Dunn index
Stability: average proportion of non-overlap, average distance, average distance between means, figure of metrit.
CLARA
CLARA is used in another python ML project. Compared to k-means clustering, CLARA is an extention of k-medoids methods to deal with large data. It is achieved by iterative sampling and then clusterting.
Using tidymodels or tidy pipeline
DBSCAN
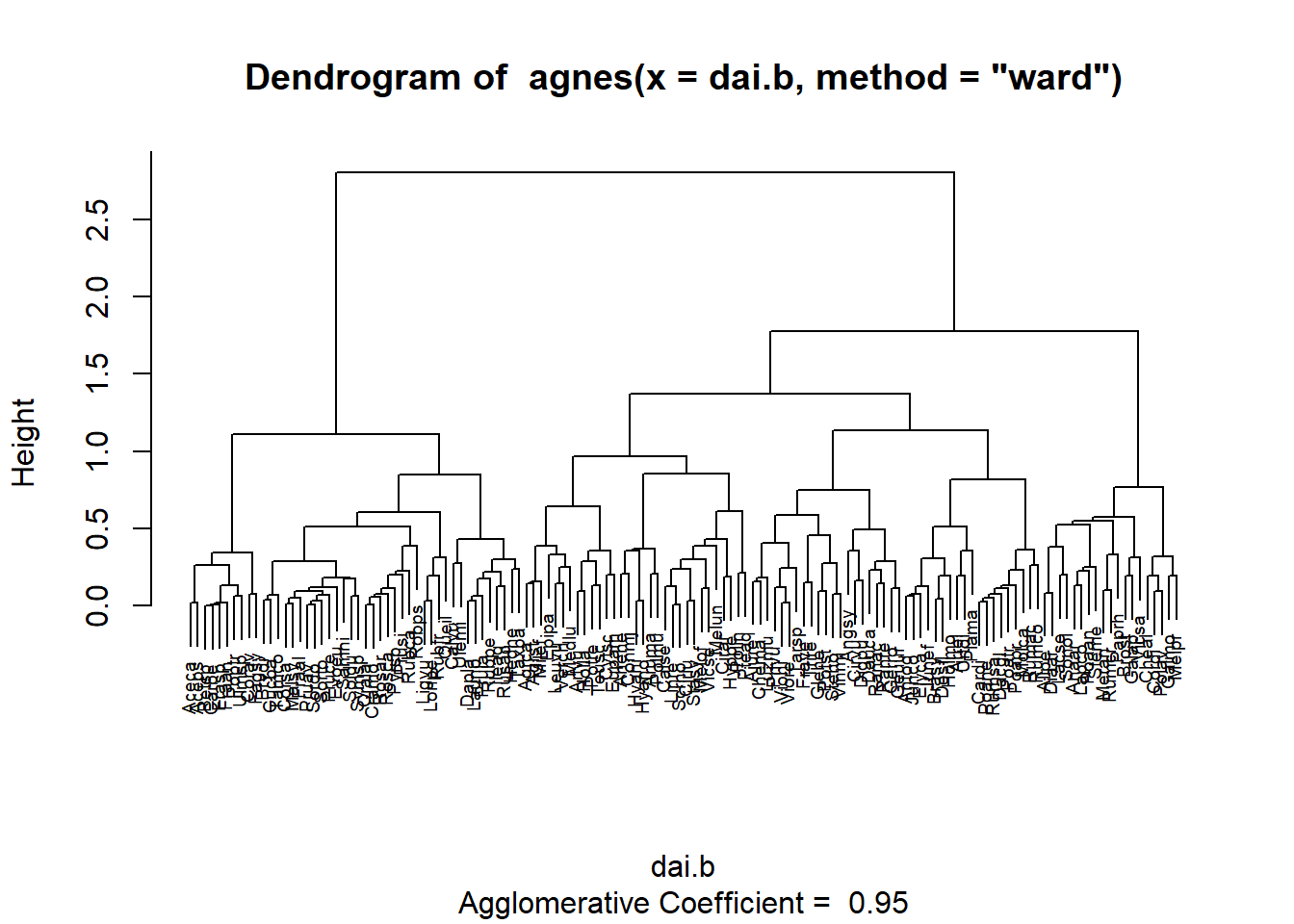
Agglomerative hierarchy clustering
library(cluster)data(plantTraits)## Calculation of a dissimilarity matrixdai.b <-daisy(plantTraits,type =list(ordratio =4:11, symm =12:13, asymm =14:31))## Hierarchical classificationagn.trts <-agnes(dai.b, method="ward")plot(agn.trts, which.plots =2, cex=0.6)